顧客名簿やイベントの参加者リスト、日々の売上データなどをスプレッドシートで管理しているとき、「同じ名前の人が二重に登録されている」「同じ注文IDのデータが重複して複数行入ってしまっている」といった問題に悩まされたことはありませんか?大量のデータを目視(手作業)でチェックして重複を探し、1行ずつ右クリックで削除していくのは、途方もない時間がかかるだけでなく、見落としや誤消去のミスが非常に発生しやすい非効率な作業です。
Googleスプレッドシートには、このような重複したデータを自動判定し、一発で削除したり、別の場所に綺麗なリストとして抽出したりする強力な機能が複数備わっています。重複データを瞬時に整理できるようになれば、データの精度が劇的に向上するだけでなく、面倒なデータ確認作業に時間を奪われることも完全になくなります。今回は、重複データを安全に削除・整理し、スマートに仕事を終わらせて定時退勤を実現するための、スプレッドシートでの重複削除・抽出設定テクニックを詳しくご紹介します!
- 重複データがあることで、売上や顧客数の「二重カウント」が発生し、ビジネス集計の正確性が失われること
- スプレッドシートの標準機能「重複を削除」を使えば、任意の列を判定基準にして重複行を一括消去できること
- UNIQUE(ユニーク)関数を使えば、元の表のデータを壊さずに、重複のないきれいな一覧を自動で別枠に抽出できること
- COUNTIF(カウントイフ)関数を条件付き書式と組み合わせることで、重複セルに自動で色を塗り、削除前に目で見て確認できること
ジャンプできる目次📖
重複データを削除するメリットと3つのやり方
データベース内の「重複した無駄なレコード」を排除する作業は、IT業界では「データクレンジング(データ洗浄)」と呼ばれ、業務プロセスの品質を保証する極めて重要な工程です。スプレッドシートに蓄積された生データを集計・分析の用に耐えうる綺麗なデータに仕上げるための、重複クレンジングの必要性と、スプレッドシートで利用できる3つの代表的なやり方について理解しておきましょう。
データの二重集計を防ぐクレンジングの重要性
データの中に「重複」が紛れ込んでいると、ビジネスにおいて多くの実務上の問題や機会損失が発生する原因になります。例えば、顧客リストに同じメールアドレスが複数登録されている場合、メルマガの配信システムが受信者に対して同じ内容のメールを二重・三重に送信してしまい、お客様に「しつこい、管理がずさんな企業だ」とチープな印象を与え、信頼を損ねてしまうリスク(迷惑メール報告のリスク)があります。また、売上管理シートで同じ伝票IDが二重登録されていると、売上金額や利益率が不自然に高く集計されてしまい、正しい現状分析や経営上の意思決定ができなくなってしまいます。
だからこそ、データを活用した業務を行う前に、重複データをすべて洗い流して「1レコード=1つのユニーク(一意)な事実」というクリーンな状態に保つことが不可欠なのです。スプレッドシートでは、やりたい目的に合わせて以下の3つの機能や数式を使い分けることで、あらゆる重複クレンジング作業を自動化できます。
以下に、スプレッドシートで利用できる「重複への3つの対処アプローチ」について、それぞれの特徴と使い分けのポイントを整理しました。
| 対処アプローチ | 使用する機能・関数 | メリット・特徴 | 最適な利用シーン |
|---|---|---|---|
| 重複データを直接一括削除 | 「重複を削除」ツール(標準機能) | 最も簡単で素早く、元の表から重複行そのものを綺麗に消去できる。 | 元データのゴミを完全に消し去って表を整理したいとき |
| 重複のないリストを別枠抽出 | UNIQUE(ユニーク)関数 | 元の表はそのままの状態で、重複のないきれいな一覧を別の列やシートに数式でリアルタイム抽出する。 | マスタデータを壊さずにユニーク一覧を作成したいとき |
| 重複データを色塗りで目視確認 | 条件付き書式 + COUNTIF関数 | 重複しているセルだけに自動で色が塗られるため、削除する前に自分の目でチェック・修正ができる。 | 本当に消してよいか、事前にデータの内容を目視確認したいとき |
このように、とにかく最速で表をクリーンにしたい場合は『重複を削除機能』が最も適しています。一方で、分析用の数式を組みたい場合は『UNIQUE関数』、消す前に安全確認をしたい場合は『COUNTIFによるハイライト』と使い分けるのがスマートです。次の章から、それぞれの具体的な設定方法と、安全に重複データをコントロールするためのポイントを詳しく解説していきます!
「このリスト、重複がないか2人で目で見てダブルチェックしてください」といった上司からの指示は、作業効率を著しく低下させる要因です。人間の目は疲労によって必ず見落としを起こします。スプレッドシートの重複検出機能を使えば、0.1秒で1万行のデータをコンピューターが完璧に検査してくれます。不確実な手作業を廃止し、システムに検査を任せて作業時間をゼロにし、サクッと定時で退勤しましょう!
【基本編】「重複を削除」機能を使ってデータを一括クリアする手順
Googleスプレッドシートに標準搭載されている「重複を削除」機能は、データの一括クレンジングに最も便利で高速な方法です。数千件、数万件のレコードが含まれる大きな表であっても、わずか3ステップの操作だけで、重複している行(レコード)を検出し、そのうちの「2行目以降」を自動的に完全に消去してくれます。手順を詳しく解説します。

ステップ1:対象の表全体または特定の列の範囲を選択する
まず、重複チェックの対象となる表全体の範囲を選択します。表のどこか1つのセルを選択した状態で、キーボードの「Ctrl + A」を押すと、表全体を綺麗に選択できます。
この際、見出し(ヘッダー)行を含めて選択してしまって問題ありません。スプレッドシートの重複削除ツールには、ヘッダーをデータ行として扱わない(削除しない)ための便利な設定項目があらかじめ備わっています。また、特定の1つの列(例: メールアドレスが入っている「C列」だけ)の重複をチェックしたい場合は、C列の列記号(一番上の「C」という文字)をクリックして列全体を選択した状態にしても動作します。
ステップ2:「データ」メニューから「データクレンジング」>「重複を削除」を選ぶ
範囲を選択した状態で、スプレッドシートの上部メニューバーにある「データ」をクリックします。
表示されたプルダウンメニューから、「データクレンジング」にマウスポインターを合わせ、さらに展開されたメニューから「重複を削除」をクリックします。画面中央に「重複を削除」の専用ダイアログボックスが表示されます。
ステップ3:キーとなる列(重複判定の基準列)を指定して実行する
ダイアログが表示されたら、重複を判断する基準となる列を指定します。以下の設定手順に沿って調整してください。
- 「データにヘッダー行が含まれる」にチェックを入れる
選択した範囲の1行目に見出し(「名前」「注文ID」など)がある場合は、必ずこのチェックボックスをオン(有効)にします。オンにすることで、見出し行が削除対象外になり、下の列リストが「列A」「列B」ではなく、実際の「名前」「注文ID」といった見出し名で分かりやすく表示されるようになります。 - 重複を判定する「分析対象の列」を選択する
- すべての項目が完全に一致する行を削除したい場合:「すべて選択」にチェックを入れたままにします。
- 特定の項目(例: 「注文ID」など)の重複だけを判定したい場合:一旦「選択解除」をクリックしてすべてのチェックを外し、重複チェックの判定基準にしたい列(例:「注文ID」が入っている列のみ)に個別にチェックを入れます。この場合、指定した列のデータが重複していれば、他の列(金額や日付など)に異なる値が入っていても、重複行として自動で削除されます。 - 「重複を削除」ボタンをクリックする
設定が完了したら、右下の青い「重複を削除」ボタンをクリックして実行します。
実行後、処理結果を伝えるダイアログ(例:「重複する行が15行見つかり、削除されました。重複しない行が85行残っています。」など)が表示されます。「OK」をクリックすれば、クレンジングが完了したスッキリした表が完成します。
- 基本は「注文番号」や「顧客ID」、「メールアドレス」といった、本来世界に1つしか存在しないユニークな値が入っている列を基準に設定すること。
- 「氏名(同姓同名)」や「部署名」などの列だけで重複削除を実行してしまうと、たまたま同じ漢字の別人のデータや、同じ部署に所属するメンバーの別のデータ行までゴッソリ消去されてしまう悲劇が起きるため、注意が必要です。
この「重複を削除」機能は、スプレッドシート上のデータを直接消去して上書きする破壊的な機能です。もし判定基準となる列の指定を間違えて、本来残しておくべきデータまで消去してしまった場合、ファイルを一度閉じてしまうと元に戻せなくなります。実行前には必ず、作業用シートをコピーして「バックアップ(控え)」を作成しておくか、間違えた直後にすかさずショートカット「Ctrl + Z(元に戻す)」を押して取り消すようにしてください。
【応用編】UNIQUE関数での自動抽出と重複セルのハイライト表示
基本編の機能は非常に強力ですが、「元のデータベースのデータを直接消してしまう」というリスクがありました。実務においては、「元の履歴データやログはそのまま残しておき、分析やアンケートの集計用に重複のないユニークな一覧を別の列やシートに表示させたい」というシーンが数多くあります。また、「いきなり消すのではなく、まずは重複しているセルがどれなのかを目で見て確かめてから判断したい」というケースもあるでしょう。これらの高度な要望に答えるための、関数や条件付き書式を用いたスマートな応用テクニックを解説します。
① UNIQUE関数:元の表を変更せずに重複のない一覧を別枠に自動生成する
スプレッドシート独自の非常に便利な関数であるUNIQUE(ユニーク)関数を使えば、指定した範囲から重複する行を取り除いた「一意なデータリスト」を数式によってリアルタイムで別枠に抽出できます。構文は極めて単純です。
=UNIQUE(範囲)具体的な設定手順は以下の通りです。
- 抽出結果を表示したい「空いている場所の左上セル」を1つだけ選択する
例えば、別シートのA2セルや、同じシートの空いている列のG2セルをクリックします。 - UNIQUE関数を入力する
元のデータベースの範囲(例:A2:C100)を指定して関数を入力します。
例:=UNIQUE(A2:C100) - Enterキーを押す
指定した範囲から重複行が自動で除外され、選択したセルの下および右方向に向かって、一意なリストが一斉に展開(スピル)されます。
UNIQUE関数の最大の強みは、「元データの変更に合わせて結果がリアルタイムで自動更新される」点にあります。元データの表の末尾に新しい商品や顧客の名前を追加すると、UNIQUE関数で抽出した先のリストにも即座に自動反映されます。これにより、手動で重複削除コピペをやり直す必要が完全になくなり、管理業務を極限まで自動化できます。
- 単体で使うだけでなく、SORT(ソート)関数と組み合わせて「
=SORT(UNIQUE(A2:A100))」と入力すれば、重複を削除した上で、五十音順(アルファベット順)にピシッと並べ替えた美しいリストが自動で完成します。 - データ件数を数えたい場合は、COUNTA(カウントエー)関数と組み合わせて「
=COUNTA(UNIQUE(A2:A100))」と入力することで、顧客リストに「何人のユニークな顧客が登録されているか(重複を除いた実数)」を瞬時に算出できます。
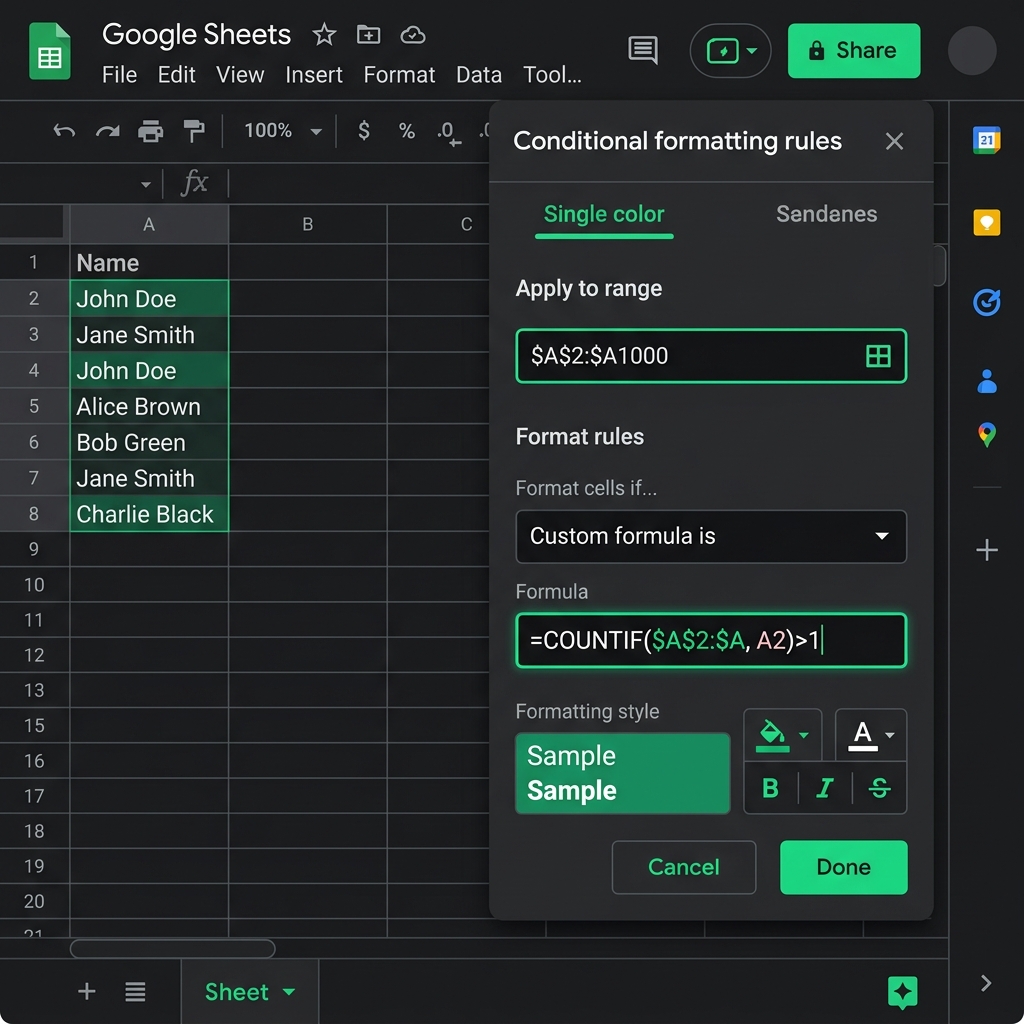
② 条件付き書式 & COUNTIF関数:重複しているセルを赤色で目立たせて確認する
「本当に重複しているのか確認してから消したい」「データを消さずに、二重登録されている箇所を見つけて修正したい」という場合は、条件付き書式にCOUNTIF(カウントイフ)関数を組み込んで、重複データが入力されているセルを自動で色塗り(ハイライト)するのが最も確実です。
設定手順は以下の通りです。
- 重複チェックを行いたいセルの範囲を選択する
例えば、顧客IDが入力されている「A2:A100」のセル範囲を選択します(このときも見出し行のA1は除外して選択します)。 - 「条件付き書式」の設定画面を開く
上部メニューの「表示形式」>「条件付き書式」をクリックし、右側に設定サイドバーを表示させます。 - セルの書式設定条件で「カスタム数式」を選択する
プルダウンから「カスタム数式」を選択し、入力テキストボックスに以下のCOUNTIF関数を使った数式を半角で入力します。
例:=COUNTIF($A$2:$A$100, A2)>1 - 書式(セルの色)を指定して「完了」をクリックする
「書式設定のスタイル」から薄い赤やピンクの背景色を選択し、「完了」をクリックします。
この設定により、範囲「A2:A100」の中で、同じデータが「2回以上」登場しているすべてのセルが自動で赤くハイライトされます。COUNTIF関数は「指定範囲($A$2:$A$100)の中で、自分と同じ値(A2)がいくつあるかを数える」という処理を行っており、それが「1より大きい(つまり2個以上ある)」場合にのみ書式を適用するという命令になっています。このハイライト表示をガイドにして、重複データを安全に確認・手修正できます。
カスタム数式に入力するCOUNTIFの第一引数(検索範囲)には、必ず「$A$2:$A$100」のように行と列の両方の前に「$」マークを付けて絶対参照で固定してください。ここが「A2:A100」のように固定されていないと、セルの判定が下に進むにつれて判定範囲まで下にスライドしてしまい、重複しているはずのセルに色が塗られないなどの誤作動が発生します。一方で、第二引数の「A2」には「$」を付けないことで、各行のセル自身の値を順番に見に行く相対参照にします。
条件付き書式による自動ハイライトを設定しておけば、手作業でデータを検索(Ctrl + F)して1つずつ調べるような手間は一切なくなります。重複が自動的に視覚化されるため、入力ミスの発見と修正にかける時間が激減します。効率的にデータをメンテナンスする仕組みを作り、作業時間を節約してサクッと定時退勤を勝ち取りましょう!
スプレッドシートの重複削除に関するFAQ
スプレッドシートで重複データを削除したり、UNIQUE関数や条件付き書式を使ったりする際によくある疑問やトラブルについてQ&A形式で解説します。実務での確実なデータ運用の参考にしてください。
Q1:大文字・小文字や半角・全角のわずかな表記違いの重複はどう判定されますか?
スプレッドシートの「重複を削除」機能は、英字の「大文字と小文字(Apple と apple)」は区別せず、同じ値(重複)として判定して削除します。しかし、「全角と半角」や「スペースの有無」は完全に異なるデータとみなされるため、重複として自動削除されません。
例えば、以下のデータはシステム上、別物と判定されてどちらもシートに残ってしまいます。
- 「田中 太郎」(全角スペース)と「田中 太郎」(半角スペース)
- 「123」(全角)と「123」(半角)
- 「株式会社ABC」と「株式会社 ABC」(スペース混入)
これらを綺麗に重複削除するためには、重複判定を実行する前に、データの表記を統一する「前処理(データクレンジング)」が必要です。具体的には、TRIM(トリム)関数を使って余分なスペースを自動削除したり、データをメモ帳などにコピペして全角英数を半角に一括変換したりした上で、重複削除ツールを実行するのがベストプラクティスです。
Q2:重複しているデータの「2行目以降」ではなく「1行目」を削除することはできますか?
スプレッドシートの「重複を削除」機能は、必ず「最も上にある行(最初に出現したデータ)」を残し、下にある2行目以降のデータを重複として削除する仕様になっています。そのため、直接「1行目を消して下の行を残す」という設定変更はできません。
もし、「最新の日付の行(表の下部にあるデータ)を残して、古い行(上部のデータ)を削除したい」という場合は、以下の手順で並べ替えを行ってからツールを実行します。
1. 表全体を選択し、データメニューの「シートを並べ替え」または「範囲を並べ替え」から、日付列やID列を「降順(Z→A、新しい順)」で並べ替えます。
2. 最新のデータが表の最上部(1行目)に移動した状態になります。
3. この状態で「重複を削除」を実行します。すると、最上部にある最新のデータ行が維持され、下部に押しやられた古い重複データが綺麗に削除されます。
Q3:UNIQUE関数で抽出したリストの中に、自分で文字を入力して追加することはできますか?
いいえ、UNIQUE関数によってデータが自動展開されているセル範囲(青い枠線で囲まれるスピル範囲)の中に、キーボードから直接文字や数値を手入力することはできません。
UNIQUE関数は、入力された起点セルから必要な分の行数を下に自動的に拡張して表示させています。もしその拡張される予定のセル(例: リストの3行目の位置)に手動で別の文字を打ち込んでしまうと、数式の展開が遮られてしまい、数式セル自体が「#REF!(または#SPILL!)」というエラー表示に変わり、リスト全体が消えてしまいます。
もし、抽出したユニークリストに対して「備考欄を追加して個別にメモを書き込みたい」といった場合は、一度UNIQUE関数の結果範囲をコピーし、同じ場所に「形式を選択して貼り付け > 値として貼り付け」を行って数式を消去し、通常のテキストデータ化してから編集を行ってください。
まとめ:重複データを一掃してクリーンな表にし、スマートに定時退勤!
今回は、Googleスプレッドシートで重複データを効率的かつ安全に削除・抽出するための手順と、実務での応用テクニックについて詳しく解説しました。ポイントをおさらいしておきましょう。
- 元の表からデータを直接消したいときは、「データ」>「データクレンジング」>「重複を削除」を使う
- 元の表を維持しつつ、自動連動するユニークリストを別枠に作りたい場合は、UNIQUE関数を使用する
- 削除する前に目視でチェックしたい場合は、条件付き書式に「=COUNTIF($A$2:$A$100, A2)>1」を適用して色を塗る
- 重複削除の実行前には、全角半角や余分なスペースを整理しておくことで、すり抜けを防ぐ
- 最新データを残して重複削除したいときは、日付列などを降順に並べ替えてからツールを実行する
データ分析やリスト管理において、重複データは集計ミスや誤送信を引き起こす諸悪の根源です。しかし、スプレッドシートの機能を正しく理解しておけば、何時間もかけて行っていた目視での確認や行削除の手間は完全にゼロになります。スマートにデータクレンジングを自動化し、エラーのない完璧なシートを最速で完成させて、今日も気持ちよく定時に退勤しましょう!
今回ご紹介した「スプレッドシートで重複データを削除・抽出する設定方法」のテクニックに加え、スプレッドシートの業務をさらに自動化できる「スプレッドシートで共同編集できない時の原因と対処法」のコツや、「スプレッドシートでXLOOKUP関数を使う手順と基本」の解説もこちらの記事にまとめました。ムダな作業時間を極限まで減らして早く帰るために、ぜひ合わせて読んでみてくださいね。