Googleスプレッドシートで顧客リストや在庫ログなどの重要なデータを管理していると、知らぬ間に紛れ込む「データの重複」に頭を悩まされることはありませんか?手作業で1件ずつスクロールしながら探すのは時間も手間もかかりますし、見落としなどのミスが発生しやすいため、非常にストレスフルな作業ですよね。
そこで最も信頼できる解決策となるのが、条件に一致するセルの個数を数える「COUNTIF(カウントイフ)関数」を使った重複データのチェック方法です。この関数を活用すれば、データの重複を自動的に検出し、ハイライト(色付け)して視覚的に整理したり、入力された時点で未然にブロックしたりすることが簡単にできるようになりますよ。
- データ重複が引き起こすビジネス上の深刻なリスクと業務効率の低下
- COUNTIF関数の基本構文と「重複=カウント数1より大きい」の判定ロジック
- セル参照における絶対参照と相対参照の組み合わせの重要性
- 標準の「重複を削除」機能とCOUNTIF関数を用いた仕組みのメリット・デメリット比較
ジャンプできる目次📖
スプレッドシートでの重複データ問題とCOUNTIF関数の役割
複数人で同じスプレッドシートを共同編集していたり、Webフォームから送信されたデータをコピー&ペーストでまとめたりしていると、どうしても発生してしまうのがデータの重複です。重複データは単に「シートの見た目が少し不格好になる」というレベルの問題ではなく、実務上の信頼性を脅かす大きな要因になります。そこで、スプレッドシートをクリーンな状態に保ち、データ分析や集計の基礎を強固なものにするために、COUNTIF関数が強力な武器として機能するのです。その具体的な影響と対策の仕組みを見ていきましょう。
データの重複が引き起こす業務効率の低下とリスク
普段何気なく扱っているデータであっても、そこに重複が含まれているだけで、ビジネスシーンでは予期せぬトラブルやコストの無駄遣いが発生してしまいます。もっとも身近な例として挙げられるのが、顧客リストをベースにした各種アプローチです。例えば、メルマガ配信やキャンペーン案内メールを送信する際、同じメールアドレスが重複して登録されていると、同一人物にまったく同じメールが何通も届くことになります。これを受け取ったお客様側としては、「この会社は個人情報の管理やシステムの連携がしっかりできていないのではないか」と不信感を抱く大きなきっかけになりかねません。また、郵送DMなどの場合は、重複している分だけ印刷代や郵送費用がそっくりそのまま無駄になってしまい、会社の予算を直接圧迫することになります。
さらに、ビジネスの重要な意思決定を左右する「集計作業」において、重複データは天敵と言えます。例えば、売上ログに同じ取引が二重に計上されていたり、同一の顧客が別々の行で複数回カウントされていたりすると、コンバージョン率(成約率)や客単価、正確な顧客数などの統計データがすべて歪んでしまいます。この歪んだデータを信じて経営判断やマーケティング施策を行ってしまうと、本来立てるべきだった戦略から大きく外れてしまう危険性すらあります。このように、データが重複していることは業務全体の信頼性を根本から揺るがす重大なリスクを秘めているのです。
重複データがビジネスに及ぼす主なリスクとデメリット:
・同一人物への多重アプローチによる、企業やブランドに対する顧客の不信感増大
・メール配信ツールの通数上限オーバーや、DM郵送コストの物理的な無駄遣い
・二重計上による売上や在庫データの狂い、それらに起因する誤ったビジネス判断
・データクレンジング(データの整理作業)のために発生する突発的な修正作業と作業工数の増加
こうした深刻な問題を防ぐために、データの「健康診断」として役立つのがCOUNTIF関数です。この関数を使うことで、リスト内に存在するデータが「それぞれ何回出現しているか」を瞬時に見える化できます。本格的な集計やグラフ作成に取り掛かる前に、この関数でサッとデータ全体のクリーンさを診断しておくことで、後から「計算が合わない!」と頭を抱えて数式を見直すような悲劇を防ぐことができますよ。
COUNTIF関数の基本構文と重複判定の仕組み
では、重複データを検出する仕組みの肝となる「COUNTIF関数」の基本を確認しましょう。この関数は、指定したセルの範囲の中から、特定の条件に合致するセルがいくつあるかを数えるためのものです。まずは記述のルール(構文)を見てみましょう。
COUNTIF関数の基本構文:
=COUNTIF(範囲, 条件)
この構文は大きく分けて2つの引数で構成されています。
- 範囲: 検索の対象にしたいセルの範囲を指定します(例:A列全体を表す
A:Aや、特定の行範囲を表す$A$2:$A$100など)。 - 条件: 数え上げの基準となる値や条件を指定します。ここに調べたいセル自体(例:
A2)を指定することで、そのセルと同じ値が範囲内に何個あるかを数えることができます。
実際に重複判定の数式を組む際は、条件にチェック対象のセルを指定し、それが「1より大きいか(=2つ以上存在するか)」を評価させることになります。具体的には、=COUNTIF($A$2:$A$100, A2)>1 という書き方をします。この数式において、範囲の始まりと終わりに「$」マークをつける絶対参照を使うのが非常に重要なテクニックです。なぜなら、この数式を下のセルへとコピーしていった際、絶対参照で指定した「範囲」は固定されたまま、第2引数の「条件(A2)」だけが相対的に「A3」「A4」とずれていってくれるからです。これにより、常に同じリスト全体をターゲットにしたまま、各行のデータがそれぞれ何回登場しているかを自動で正しくカウントできるようになるのですよ。
この関数の出力値が「2」以上、つまり >1 という不等式が成り立つ場合、スプレッドシートは結果として「TRUE(真)」という値を返します。逆に、その範囲内に1つしか存在しないユニークな値であれば、COUNTIFの戻り値は「1」になるため、>1 は成り立たず「FALSE(偽)」となります。この「TRUEかFALSEか」という結果を利用することで、スプレッドシートの条件付き書式(セルの色付け機能)を動作させたり、フィルターで重複している行だけを絞り込んで削除したりすることが可能になるのです。
なお、スプレッドシートで大量のデータを取り扱う場合、関数を多用しすぎると動作スピードに影響が出ることがあります。もし「なんだか動作が重くなってきたな」と感じたら、こちらの記事()を読んで、パフォーマンスの改善を試みてくださいね。大量のデータでもサクサク動かすためのノウハウが詰まっていますよ。
ここで、スプレッドシートの標準メニューに搭載されている重複削除機能と、COUNTIF関数を使った重複判定方法を比較してみましょう。どちらにも得意分野がありますので、実務のシーンに応じて最適な方法を選べるようになると、さらに効率がアップしますよ。
| 比較項目 | スプレッドシートの標準機能(重複を削除) | COUNTIF関数を用いた重複チェック |
|---|---|---|
| 柔軟性(ターゲット) | 重複しているデータを一括で消去するため、どのデータが重複していたかを残すのが難しい(元データの保持が不可)。 | 元データを削除することなく、重複している行やセルをハイライトしたり、フラグを立てて残せる(元データの保持が可能)。 |
| 動的なスケーリング | 新しくデータが追加された場合、その都度メニューから機能を手動で実行し直さなければならない(静的な処理)。 | 数式や条件付き書式が自動的に再計算されるため、新規データが追加された瞬間にリアルタイムで重複が検知される(動的な処理)。 |
| 条件のカスタマイズ性 | 「完全に一致する値の削除」といったシンプルなルールに限定され、細かい条件の変更は行えない。 | 「2回目以降に出現した重複のみを色付けする」「特定のフラグが立っている場合のみ重複カウントする」など、自由な条件設定が可能。 |
| シートの動作への依存 | 一度実行してデータが削除されれば計算式は残らないため、どれだけデータ件数が多くても動作が重くなる原因にならない。 | セルの状態を常に監視して数式が計算され続けるため、数万件規模のシートに適用すると再計算による動作低下が起こることがある。 |
このように、単純に不要なデータを今すぐ一度に削除したいだけであれば標準機能の「重複を削除」が非常に手軽で効果的です。しかし、「どのデータが重複しているのかを目視で精査しながら作業を進めたい」「新しく入力された重複データに対して即座に警告を出したい」といったビジネスの現場でよくある柔軟かつ動的な運用を行いたい場合には、COUNTIF関数を使ったアプローチが圧倒的に強力な解決策となりますよ。それぞれの特性をしっかりと理解して使い分けることで、スプレッドシートでのデータ管理が驚くほどスムーズになるはずです。
COUNTIF関数を使って重複データを一括チェック・抽出する基本手順
Googleスプレッドシートで顧客管理用の名簿や商品の在庫マスターなどを扱っていると、知らない間に同じデータが何度も登録されてリストが散らかることがありますよね。例えば、同じメールアドレスや商品型番が別々の行に入力されているケースです。
もちろん、標準機能の「重複を削除」を使えば一発で消去できますが、この機能はいきなりデータを削除するため、「削除する前にどちらのデータを残すべきか目視で確認したい」という場面では不向きです。そこで大活躍するのが、COUNTIF(カウントイフ)関数を使った重複チェックの方法ですよ。この方法なら、元のデータを消すことなく、どのデータが何回出現しているかを安全にカウントし、重複データだけを浮き彫りにできます。このセクションでは、作業用の列を追加してCOUNTIF関数を入力し、実際に重複データを抽出するまでの基本手順を解説しますね。

作業用の「重複チェック列」を作成してCOUNTIFを入力する手順
スプレッドシートで重複データを安全に探し出す最初のステップは、作業用の「重複チェック列」を作成することです。既存のデータ列に直接手を加えないため、元のデータが壊れる心配がなく安心ですよ。
具体的な手順を説明しますね。まず、重複をチェックしたいデータ(例えばA列の「メールアドレス」など)の隣に、新しく空の列を挿入します。A列のヘッダーを右クリックして「右に1列挿入」を選択し、1行目のセルに見出しとして「重複チェック」や「出現回数」と入力しておきましょう。
次に、作成した新しい列の2行目のセル(B2セル)に、以下のCOUNTIF関数を入力します。
=COUNTIF($A$2:$A, A2)
この数式は、重複をカウントする際の最も標準的な記述ですよ。COUNTIF関数は =COUNTIF(範囲, 条件) という構造をしています。今回の数式でいうと、第1引数の範囲にあたる $A$2:$A は、重複を調べたいデータの開始位置から最下部までを示しています。そして、第2引数の条件にあたる A2 は、現在チェックしている行のデータです。つまり、「A列全体の中から、A2と同じデータが何個あるかを数えてね」という命令になりますね。
ここで重要なのが、範囲の始まりにある「$」マークです。$A$2 のように指定することで、数式を下のセルにコピーしても開始位置がずれない「絶対参照」としてロックできます。後半の「:$A」は、スプレッドシート独自の便利な記述方法です。Excelと違って行番号を省略して「:$A」と書くことで、「シートが下方向にどれだけ伸びても、列の最後まで自動で範囲に含める」という動的な指定ができます。データが新しく追加されても、数式を直すことなく自動でチェック対象に含められるのが嬉しいですね。
数式を入力したら、B2セルの右下角にある青い四角(フィルハンドル)をダブルクリックして、数式を最下部までオートフィルでコピーします。
コピーが完了すると、重複チェック列に数字が表示されます。
- 表示された数値が「1」であれば、そのデータはシート内で唯一のユニークデータです。
- 表示された数値が「2以上」であれば、そのデータはシート内で「重複しているデータ」であることを示していますよ。
結果を確認したら、重複しているデータだけを画面に抽出してみましょう。メニューの「データ」から「フィルタを作成」を選択します。重複チェック列のフィルタアイコンをクリックし、一度「クリア」をクリックしてすべてのチェックを外した後、「2以上の数値(2や3など)」だけにチェックを入れて「OK」をクリックします。
これで画面上には、重複しているデータが入っている行だけがピンポイントで表示されました!この状態であれば、どのデータが重複しているのかを目視でじっくり比較検討できますし、背景に色を塗って目立たせるなどの作業がスムーズに行えますよ。
作業列を使った重複チェックのポイント
- 作業用の列を新たに挿入し、元のデータを壊さない安全な環境を作る
=COUNTIF($A$2:$A, A2)を使い、チェック範囲の始まりを「$」で固定する- チェック列の数値が「2以上」の行をフィルタリングして、重複を一括抽出する
なお、COUNTIF関数は非常に便利ですが、数万行に及ぶような巨大なシートで大量に使用すると、スプレッドシートの動作が著しく重くなってしまうことがあります。もし動作速度が気になったら、こちらの記事()もあわせて参考にしてみてくださいね。サクッと動作を軽くするコツをたくさん紹介していますよ。
2回目以降の重複のみをピンポイントで抽出する範囲ロック(相対参照)の裏ワザ
基本的なCOUNTIF関数の使い方では、データが重複している場合、最初に出てきた行も2回目に出てきた行も、すべての結果が「2」や「3」といった同じ数字になってしまいます。例えば「Aさん」が2行目と5行目に重複していたら、B2セルもB5セルもどちらも結果は「2」になりますね。
この状態のまま、フィルタで「2以上」を抽出して行を丸ごと削除してしまうと、2行目も5行目も両方のデータが消えてしまうため、リストから「Aさん」の情報が完全に失われてしまいます。これでは困りますよね。
そこで、重複データを整理する際に役立つのが、「2回目以降に登場する重複データだけをピンポイントで見つけ出す」という範囲ロック(相対参照)を応用した裏ワザ数式ですよ。入力する数式は以下の通りです。
=COUNTIF($A$2:A2, A2)
先ほどの数式とほとんど同じに見えますが、コロンの後ろ側が「:$A」ではなく、ドルマークのない相対参照の「A2」になっているのが大きな違いです。
この $A$2:A2 という記述は、先頭の $A$2 は絶対参照で固定されていますが、後ろの A2 はコピーしたときに自動で変化する相対参照のままになっています。この数式を下のセルへコピーしていくと、スプレッドシート内部では参照範囲が以下のように自動で広がっていきます。
- 2行目(B2):
=COUNTIF($A$2:A2, A2)―― A2からA2の範囲でA2をカウント - 3行目(B3):
=COUNTIF($A$2:A3, A3)―― A2からA3の範囲でA3をカウント - 4行目(B4):
=COUNTIF($A$2:A4, A4)―― A2からA4の範囲でA4をカウント - 5行目(B5):
=COUNTIF($A$2:A5, A5)―― A2からA5の範囲でA5をカウント
この仕組みは、全体の範囲を調べるのではなく、「データの最上部(2行目)から、現在自分がいる行までの範囲」の中で、そのデータが何回出現したかを数えるということです。つまり、その行のデータが「その時点で何回目の登場なのか」をカウントしているのですね。
これによって、返ってくる数値に大きな違いが生まれます。「Aさん」が2行目と5行目に存在する場合、
- 2行目のB2セルでは、範囲が $A$2:A2 (2行目だけ)なので結果は「1」になります。
- 5行目のB5セルでは、範囲が $A$2:A5 (2行目から5行目)に広がり、2行目と5行目の「Aさん」が両方含まれるため結果は「2」になります。
このテクニックを使えば、最初に登場したオリジナルデータは結果が必ず「1」になり、2回目以降に登場した重複データは結果が「2以上」になります。同じ重複データであっても、「オリジナル」と「余分なコピー」を明確に区別できるのですね。
この設定をしておけば、データの整理が劇的に簡単になりますよ。フィルタで「重複チェック列」から「2以上の数値」だけを絞り込んで抽出してみてください。画面上には、1回目に登場したオリジナルの行(カウントが1の行)は非表示になり、2回目以降に出現した「純粋に重複している余分な行」だけが綺麗に並びます。
あとは、表示されている行をすべて選択して右クリックし、「選択した行を削除」を実行するだけ!フィルタを解除すれば、重複データが一掃され、最初の1件だけが残った綺麗なリストが完成しますよ。手動でどれを消すか探す必要はもう一切ありませんね。
KYOのワンポイント解説:Excelと共通の超名作テクニック
今回ご紹介した「片側だけドルマークを固定して範囲を拡張させる($A$2:A2)」という参照テクニックは、スプレッドシートだけでなく、Excelの実務でも非常によく使われる有名な手法ですよ。これを使うことで、累計値の計算や行ごとの連番作成など、応用範囲がグッと広がります。数式を入力する際、キーボードの「F4」キーを押すことでドルマークの付け方を切り替えることができるので、ぜひ覚えておいてくださいね。
COUNTIF関数の範囲指定を少し工夫するだけで、手動でのデータ整理にかかる時間が大幅に削減でき、ミスも劇的に減らすことができますよ。あなたのスプレッドシート作業を快適にするために、ぜひこの範囲ロックの裏ワザを日々の業務で活用してみてくださいね。
条件付き書式とCOUNTIFを組み合わせて重複行全体に色を付ける応用手順
スプレッドシートでデータの重複をチェックするとき、セルに数式を入力して「重複」と表示させるだけでも十分に便利ですが、データ量が多くなってくると、視覚的にパッと見で見分けられたらもっと嬉しいですよね。そこで大活躍するのが「条件付き書式」という機能です。条件付き書式を使えば、重複しているデータが存在するセルや、そのデータが含まれる行全体に自動で好きな色を塗ることができます。
色が付くことで、大量のリストの中から「どれが重複しているデータなのか」が瞬時に判別できるようになります。目視での確認や削除の作業効率が劇的にアップしますし、チェック漏れによるミスを防ぐのにも役立ちますよ。今回は、スプレッドシートの便利機能である条件付き書式に、これまで学んできたCOUNTIF関数を組み合わせて、重複データを自動的に色分けする具体的な設定手順を解説していきます。
特に、特定のセルだけでなく「重複データがある行全体に色を塗る」というテクニックは、実務で非常によく使われる応用技です。これができるようになると、スプレッドシートの操作レベルが一段上がること間違いなしですので、ぜひ私と一緒に設定手順を確認しながら、マスターしていきましょうね。
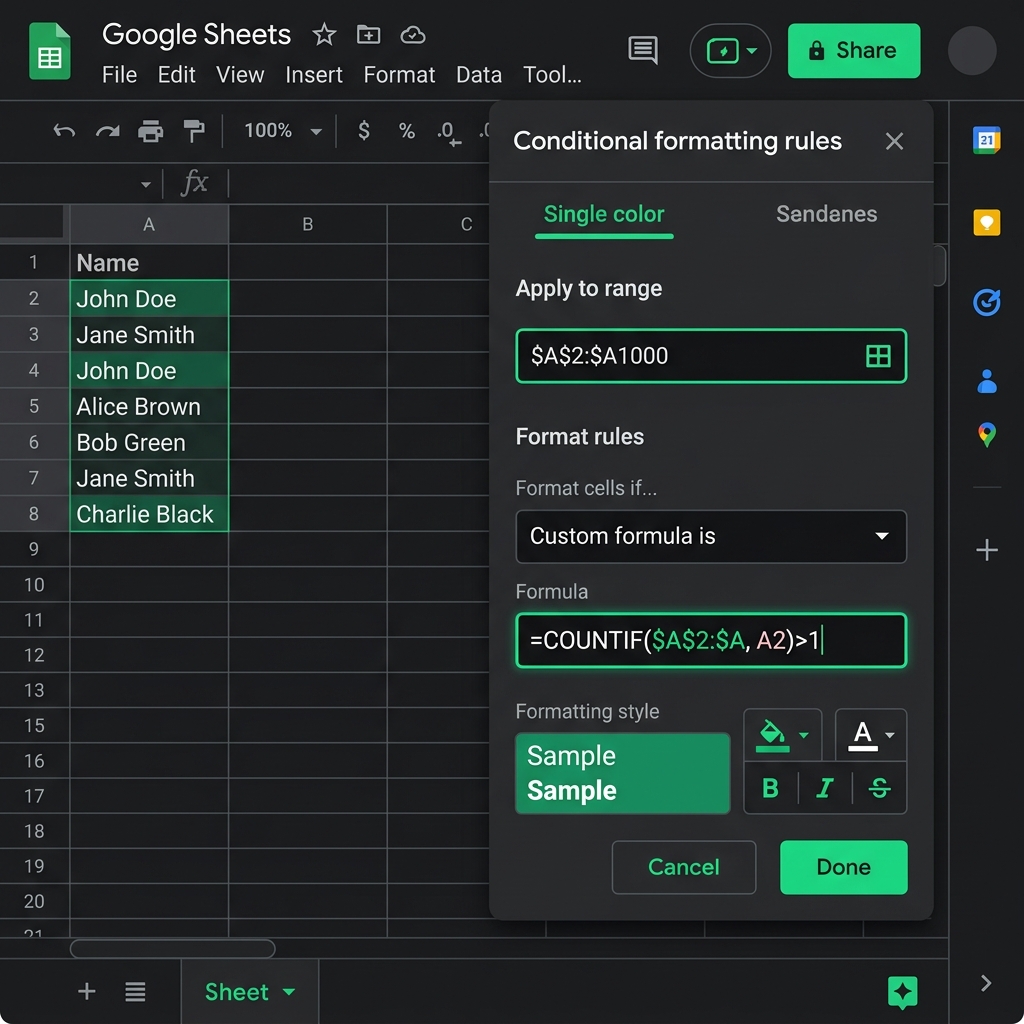
条件付き書式の「カスタム数式」にCOUNTIFを組み込む設定手順
まずは、特定の列の中で重複しているセルを見つけ出し、そのセル単体に自動で色を付ける基本の手順から進めていきましょう。条件付き書式にはいくつかの標準ルールが用意されていますが、COUNTIF関数を使って複雑な条件を指定するためには、「カスタム数式」という設定方法を使用します。初めて触る方にとっては少し難しく感じるかもしれませんが、手順通りに進めれば簡単ですので安心してくださいね。
例として、A列の2行目から下(A2:A)に入力されている顧客IDやメールアドレスなどのデータの中で、重複しているセルに色を付けてみます。具体的な手順は以下の通りです。
最初に対象となるセル範囲を選択します。今回の例ではA列のデータ部分ですので、A2セルをクリックした状態で、キーボードの「Ctrl + Shift + ↓」(Macの場合は「Cmd + Shift + ↓」)を押して、データが入っている一番下のセルまで選択しましょう。あるいは、シンプルに範囲指定の入力欄で「A2:A」と直接指定しても大丈夫ですよ。
範囲を選択できたら、画面上部にあるメニューバーの「表示形式」をクリックし、表示された選択肢の中から「条件付き書式」を選びます。すると、画面の右側に「条件付き書式設定ルール」というサイドバーが表示されます。
サイドバーが表示されたら、以下の内容を設定していきましょう。
まず、「範囲に適用」の欄に選択した範囲(例:A2:A)が入っていることを確認します。次に、「書式ルール」の下にあるプルダウンメニューをクリックします。ここには「セルが空ではない」「テキストに含まれる」など様々な条件が並んでいますが、一番下までスクロールして「カスタム数式」を選択してください。
カスタム数式を選択すると、その下に「値または数式」と書かれた入力欄が表示されます。ここに、重複を判定するためのCOUNTIF関数を記述します。入力する数式は次の通りです。
=COUNTIF($A$2:$A, A2)>1
数式を入力したら、その下にある「書式設定のスタイル」で、重複したセルに適用したいデザインを選びます。デフォルトでは薄い緑色になっていることが多いですが、目立たせたい場合は薄い赤色や黄色に変更するのがおすすめですよ。設定が終わったら、一番下にある「完了」ボタンをクリックします。これで、A列の中で2回以上登場する重複データがあるセルだけに、自動で色が塗られるようになります。
カスタム数式に入力した =COUNTIF($A$2:$A, A2)>1 の解説
この数式のポイントは、検索範囲である「$A$2:$A」にドル記号($)を付けて絶対参照にしている点です。これにより、どのセルを判定するときも検索する範囲が固定されます。一方で、判定基準となる「A2」にはドル記号を付けていません(相対参照)。こうすることで、スプレッドシートが自動的に「A2セルのデータは範囲内に2個以上あるか?」「A3セルのデータは範囲内に2個以上あるか?」と、1行ずつずらしながら判定を行ってくれるのです。最後の「>1」は、カウントした結果が「1より大きい(=2回以上現れている)」場合にのみ、色を付けるという条件を意味していますよ。
もし設定したはずなのに色が塗られない場合は、数式の入力間違いがないかを確認してみてくださいね。特に、イコール(=)やカンマ(,)、括弧、そしてドル記号($)が半角で入力されているかどうかが重要です。全角英数字が混ざっていると、スプレッドシートが数式を正しく認識できず、エラーになってしまったり何も反応しなくなったりしますので、入力モードを半角にしてから打ち込むようにしましょう。
「重複行全体」に色を付けて視認性を極限まで高める設定方法
さて、ここからがいよいよ本番です。先ほどの手順では、重複している「特定のセル」だけに色が付きましたが、実際の業務では「重複している行全体」に色を付けたいケースがほとんどではないでしょうか。例えば、名前や住所、電話番号などが並んでいる名簿リストで、名前が重複している行全体に色が付いていれば、その人の他の情報(住所や登録日など)を横並びで確認しやすくなり、どちらのデータを削除すべきかの判断が非常にスムーズになりますよね。
「重複行全体」に色を付けるためには、条件付き書式を設定する際の「範囲指定」と「数式の書き方」を少しだけ工夫する必要があります。こちらも具体的なステップに沿って解説しますので、一緒にやってみましょう。
まず、色を塗りたいテーブル(表)の全体を選択します。例えば、A列からG列までデータが入っており、見出し行(1行目)を除いた2行目から100行目までを対象にする場合は、範囲を「A2:G100」(または「A2:G」として下方向を無制限)と指定します。この「表全体を選択する」というのが、行全体に色を広げるための最初の重要なポイントですよ。
範囲を選択した状態で、先ほどと同じようにメニューの「表示形式」→「条件付き書式」を開き、右側のサイドバーで書式ルールを「カスタム数式」に設定します。
そして、入力する数式を以下のように変更してください。
=COUNTIF($A$2:$A, $A2)>1
先ほどの数式と何が違うか、気づきましたでしょうか?そうです。第2引数(判定の基準となるセル)の「A2」の部分が、「$A2」と列固定のドル記号付きになっているのです。この「$」の位置が、重複行全体に色を塗るための魔法の鍵になります。
なぜ「$A2」にすると行全体に色が塗られるの?
スプレッドシートの条件付き書式は、指定した適用範囲(今回の場合は A2:G100)のすべてのセルに対して、入力した数式を順番に実行して色を塗るかどうかを判断しています。
もし、数式を =COUNTIF($A$2:$A, A2)>1 のまま表全体に適用してしまうと、B列のセル(例えばB2セル)を判定するときに、数式が自動的に =COUNTIF($A$2:$A, B2)>1 に書き換わってしまいます。これだと、「B列のデータがA列内で重複しているか」という意図しないチェックになってしまいます。
そこで、判定基準を「$A2」と列ロック(絶対列参照)にします。これにより、B2セルを判定するときも、C2セルを判定するときも、はたまたG2セルを判定するときも、常に「A列($A)の2行目の値を基準にする」という動作になります。結果として、A2セルのデータが重複していれば、同じ2行目にあるA2からG2までのすべてのセルで条件が「成立(TRUE)」となり、行全体にきれいに色が塗られるという仕組みなのです。行番号の「2」にはドル記号が付いていないので、3行目の判定に入ると自動的に「$A3」となり、正しく次の行の重複チェックが行われますよ。
この列固定($A2)の考え方は、条件付き書式を使いこなす上で非常に重要なテクニックです。これさえ覚えておけば、重複チェックに限らず、「特定のセルの値が〇〇だったら、行全体に色を塗る」といった様々なカスタムルールを作ることができるようになりますよ。
ここで、設定する際によくあるミスと、それを防ぐための注意点を整理しておきましょう。比較表を作ってみましたので、頭の中を整理する参考にしてくださいね。
| 設定したい動作 | 適用範囲の指定 | カスタム数式の内容 | ポイントと注意点 |
|---|---|---|---|
| A列の重複セル単体に色を塗る | A2:A | =COUNTIF($A$2:$A, A2)>1 |
基準セル(A2)に「$」を付けないことで、各セルの値をそのまま判定します。 |
| A列の重複に基づいて行全体に色を塗る | A2:G100(表全体) | =COUNTIF($A$2:$A, $A2)>1 |
基準セル($A2)の列に「$」を付けて固定し、行全体が同じA列の値を参照するようにします。 |
| 【失敗例】行全体に色が塗られない、またはズレる | A2:G100(表全体) | =COUNTIF($A$2:$A, A2)>1 |
「$A2」の「$」を忘れると、隣の列(B列など)の値で判定されてしまい、色が正しく塗られません。 |
| 【失敗例】全体の行が全く同じ色になる、またはエラー | A2:G100(表全体) | =COUNTIF($A$2:$A, $A$2)>1 |
基準セルを「$A$2」と完全固定してしまうと、すべての行が「A2セルが重複しているかどうか」だけで判定されてしまいます。 |
このように、ドル記号をどこに付けるかによって動作が全く変わってしまいます。慣れるまでは「検索範囲の全体($A$2:$A)は完全に固定する(ドルを2つ付ける)」、「判定の基準($A2)は列だけ固定する(Aの前にだけドルを付ける)」とパターンで覚えてしまうのがおすすめですよ。
スプレッドシートの動作が重くなったときの対策
条件付き書式にカスタム数式を設定すると、セルの値を変更するたびにスプレッドシートが裏でCOUNTIFの計算を繰り返し実行するため、データ数が数万件規模になると動作が急に重くなってしまうことがあります。特に、行全体(A2:G10000など)に複雑な数式を適用した場合は、PCのスペックによっては画面がフリーズしたように感じることも……。
もし設定後にファイルの挙動が遅くなったと感じたら、適用する範囲を本当に必要な行数までに制限するか、あるいは不要な条件付き書式を削除して整理してみてください。根本的な軽快さを取り戻したい場合は、数式や運用の見直しも効果的です。こちらの記事で紹介しているも合わせてチェックしてみてくださいね。計算の負荷を減らす具体的な工夫を詳しく解説していますよ。
条件付き書式で重複行を色分けする方法は、一度設定してしまえば、後から新しくデータを追加したときにも自動的に判定が行われ、リアルタイムで色が塗られます。手作業で1つずつ確認して色を塗る手間が完全にゼロになりますので、リスト管理やデータクレンジングの作業が本当に楽になりますよ。ぜひあなたのスプレッドシートでも実際に手を動かして、この便利な自動色分け機能を試してみてくださいね。
スプレッドシートのCOUNTIF重複判定に関するよくある質問(FAQ)
GoogleスプレッドシートでCOUNTIF関数を使って重複データを判定できるようになると、日々のデータ管理やリスト作成の効率が劇的にアップしますよね。ただ、実際に仕事でシートを使い込んでいくと、「大文字と小文字は同じものとして扱われるの?」「重複したデータを目視で確認するだけでなく、一瞬で一括削除したいときはどうすればいい?」「数式を入れたらシート全体の動きが極端に遅くなって困っている……」といった、新たな疑問や想定外のトラブルに直面することもよくあります。
そこで今回は、スプレッドシートでの重複判定に関して、特につまずきやすいポイントやよくある疑問をFAQ形式で分かりやすく解決していきますね。これらの対処法をしっかりマスターして、エラーやストレスのない快適なデータチェック環境を整えていきましょう!
Q1:大文字・小文字、全角・半角の違いは重複としてカウントされますか?
スプレッドシートのCOUNTIF関数で重複チェックを行う際、データの「表記揺れ」によって意図した通りに判定されないケースがあります。結論から言うと、スプレッドシートのCOUNTIF関数は英語の「大文字・小文字」の違いは区別しません。例えば、半角で入力された「Apple」「apple」「APPLE」は、すべて同じデータとみなされ、重複としてカウントされますよ。入力する人によって大文字小文字がバラバラでも、自動で重複を検知してくれるのは嬉しいポイントですよね。
しかし、注意しなければならないのが「全角・半角の違い」と「不要なスペース(空白)の有無」です。これらはスプレッドシートの内部で完全に別のデータとして区別されてしまいます。
例えば、全角の「Apple」と半角の「Apple」は別データと判定されますし、末尾や途中に半角スペースが入った「Apple 」も別物扱いになります。見た目では全く違いが分からないため、「重複があるはずなのに、なぜかCOUNTIF関数でカウントされない……」というトラブルの代表的な原因になっているのですね。このようなチェック漏れを防ぐために、関数を入れる前に必ず表記を綺麗に揃えておきましょう。
スペースや全角・半角の混在に注意!
重複判定を実行する前に、データの表記揺れを整えておくことが大切です。文字の前後の余分な空白を取り除く「TRIM(トリム)関数」や、全角英数字を半角に変換する「ASC(アスキー)関数」を活用しましょう。「データ」>「データクリーンアップ」>「空白のトリム」機能を使うのも手軽でおすすめですよ。
Q2:重複行を一括で削除(削除機能)するにはどうすればいいですか?
重複を発見した後に、「確認できたので、重複している不要な行を一括で削除し、ユニークなデータだけを残したい!」と思うこともありますよね。その場合は、関数を使うよりもスプレッドシートの標準機能である「重複を削除」ツールを使用するのが最も手っ取り早くて確実ですよ。
手順は簡単です。まず、重複を処理したいデータ範囲全体を選択します。次に、メニューバーの「データ」から「データクリーンアップ」>「重複を削除」を選択しましょう。詳細設定の画面が表示されますので、重複を判定する基準にしたい列にチェックを入れ、「重複を削除」ボタンを押します。これだけで、重複していた2件目以降のデータが瞬時に消去され、ユニークなデータだけが綺麗に残りますよ。
COUNTIF関数は、元のリストの並び順を変えずに「どのデータがどれくらい重複しているかを可視化する」診断用の確認ツールです。一方で、メニューから実行する「重複を削除」は、データを物理的に消去する実行用のツールになります。
私自身もよくやっているのですが、データを壊さずに色を塗って確認したいときはCOUNTIF関数を使い、不要な重複行を今すぐ消去したいときは「重複を削除」ツールを使うといった形で、目的や作業フェーズに合わせてスマートに使い分けてみてくださいね。
Q3:COUNTIF関数を入れたらスプレッドシートが非常に重くなりました。対策は?
「データの重複チェックのためにCOUNTIF関数を数千行にコピーしたら、シート全体の動きが極端に遅くなった……」というのは、スプレッドシートあるあるの大きな悩みです。シートが重くなると、入力するのにも数秒待たされたり画面が固まったりして、作業どころではなくなってしまいますよね。
この動作遅延の原因は、COUNTIF関数で行われる「再計算のループ」にあります。特に範囲指定を「A:A」のように列全体で指定するオープンレンジ形式にしていると、スプレッドシートは最終行までの空白セルまで毎回すべてスキャンするため、計算処理に大きな負荷がかかってしまうのですね。
この「重い」問題を解決するための具体的な対策は、主に3つあります。
1つ目は、「数式の範囲指定を必要な行数だけに制限する」ことです。データが500行目までなら、=COUNTIF(A$2:A$500, A2)のように開始行と終了行を「$」記号で固定して制限しましょう。これだけでスプレッドシートが余計なセルを読み込むのを防ぎ、処理が劇的に軽くなりますよ。
2つ目は、「確認が終わったら数式を値に置き換える」方法です。チェック後にCOUNTIFが入力されている列をコピーし、同じ場所に「値のみ貼り付け」を実行して数式を消去してしまいましょう。ただの数値データに変換されるため、再計算が発生しなくなり動作が非常に軽くなります。
3つ目は、「UNIQUE(ユニーク)関数などで一括抽出する」方法です。重複を省いたユニークなリストを作成すること自体が目的なら、大量のCOUNTIFを置く代わりに別のセルに=UNIQUE(A2:A500)と1つ記述するだけで、重複を除外したリストを自動作成できます。計算するセルが1つで済むため、シートのパフォーマンスを高く保てますよ。
スプレッドシートを軽くするアプローチは他にもたくさんあります。動作速度に悩んでいる方は、こちらの記事()もぜひチェックしてみてくださいね。
まとめ:COUNTIF関数で重複を自在にコントロールして業務効率をアップし、今日も早く帰りましょう!
今回は、GoogleスプレッドシートでCOUNTIF関数を使って重複データを判定・抽出する方法について、よくある疑問への対策を含めて解説してきました。
大量のデータから手作業で重複を探し出すような、時間もかかりミスも起きやすい不毛な作業は、もう今日で終わりにしましょう。COUNTIF関数を使った重複のチェック方法や表記揺れの対策、重くなったときの対処法といったコツを少し意識するだけで、データ管理の正確性とスピードは驚くほど向上しますよ。このような小さな効率化を日々の業務に取り入れていくことが、無駄な残業をゼロにし、今日もサクッと定時退勤して大切な時間をたっぷりと楽しむための秘訣なのです。自動でできることはツールに任せて、明日からのデスクワークをもっと快適に進めていきましょうね!
正確な情報は公式サイトをご確認ください。最終的な判断は専門家にご相談ください。
なお、今回はスプレッドシートの重複判定について解説しましたが、数式を多用したことでシートが重くなってお困りの方は、以下の解決記事もぜひ参考にしてみてください。
👉
また、今回ご紹介した機能や関数の詳細については、以下のGoogle公式サポートページも併せて参照してみてくださいね。
スプレッドシートの「Googleスプレッドシートで重複をCOUNTIF関数で判定・抽出する方法」と合わせてマスターしておくと実務で非常に役立つ、「Googleスプレッドシートでセル内改行をする方法と一括置換・削除のコツ」の設定手順や、「スプレッドシートで非表示を解除できない原因と5つの対策」の活用方法について以下の関連記事で詳しく図解しています。作業効率をさらに高めて、サクッと定時で帰るためにぜひ参考にしてみてくださいね。